showed that prediction targets don't matter when the readout head is linear. showed that a 2-layer MLP breaks through. confirmed the mechanism: gradient coupling through composition (W2⊤W1⊤), not nonlinearity or bottleneck width. This is the decomposability wall — the second architectural barrier (after the sensory-motor wall).
Both walls are architectural. Neither can be overcome by more training data, better targets, or richer environments. The path to high integration requires specific computational structures.
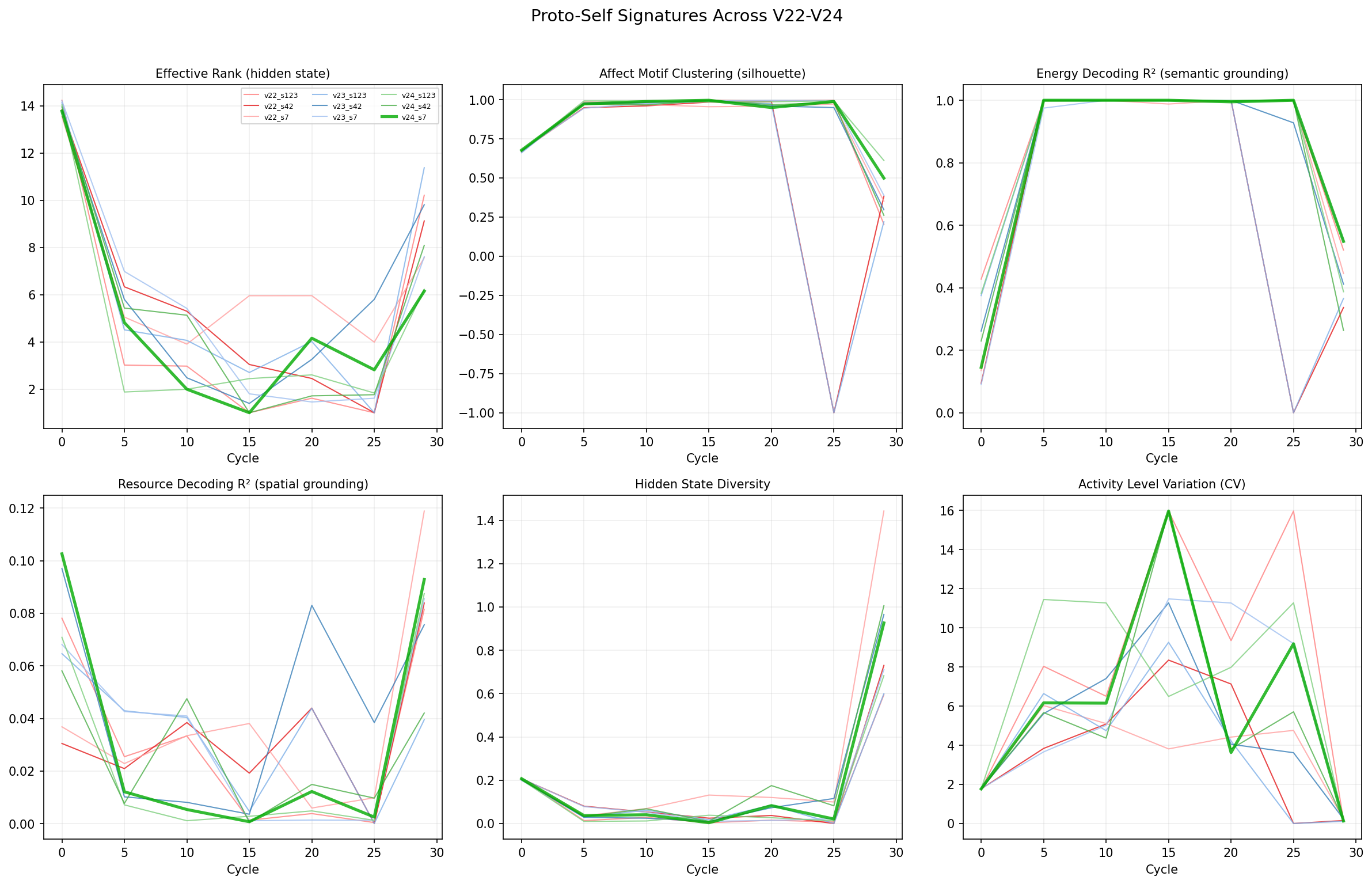
The Decomposability Wall — why composition matters. Left: linear head sends independent gradients to each hidden unit (decomposable, Φ≈0.08). Right: MLP head couples all hidden units through shared intermediate layer (integrated, Φ≈0.25). The key is gradient coupling through composition — not nonlinearity, not bottleneck width.Proto-self signatures across . Six metrics tracked over evolution for all 9 runs (3 seeds × 3 experiments). Top-left: effective rank drops at drought boundaries but recovers — states are moderately rich (4–14 dimensions). Top-center: affect motif clustering (silhouette) is mostly negative to near-zero — no behavioral modes emerge with linear readouts. Top-right: energy decoding R² is very low (0–0.2 at best) — hidden states do NOT cleanly encode energy despite the gradient specifically targeting energy prediction. Bottom row: resource decoding, hidden state diversity, activity variation — all noisy without clear trends. These are the signatures of proto-self failing to emerge under linear readout architectures. Compare with (MLP head) where silhouette reaches 0.34 and behavioral modes appear for the first time.